View all the videos from this unit a single playlist on youtube
Java I/O #
A common place where Java programmers first really experience inheritance and polymorphism in action is with I/O (input/output), so let’s take a look at it now. Not only is it something you should know as a Java programmer, but it gives us a nice case study in object oriented design. So we’re going to first try to understand the problem: what requirements do we really have of an I/O system? Then we’ll see how the Java IO package’s object oriented design meets those goals.
Reading … What’s the problem? #
I/O (input and output) is kind of what programs are all about. If we couldn’t instruct the program as to our intentions or we couldn’t somehow perceive the results produced by the program, what would be the point in running it? In this lesson we look at byte and character I/O — I/O concerning files, buffers in memory, network connections, things like that. GUI I/O will be covered later.
Designing a system for handling I/O is a daunting problem for language/library/API developers. These operations are so ubiquitous in programs that getting it wrong means making pretty much every program anyone ever writes more difficult, and getting it right means making pretty much every program anyone ever writes easier. So, let’s consider some desirable properties, some design goals, regarding reading, i.e. the “input” half of I/O. In particular, we’ll look at stream-oriented input and output.
-
Bytes or chars or tokens? Fundamentally, all data in the modern computing world is byte-oriented, and oftentimes we want to read data that way. On the other hand, often we want to read textual data - i.e. data that is character-oriented. In C, where char’s and bytes are synonymous, we don’t need to distinguish between the two. In Java, however, where characters are unicode and not generally single-byte values, we very much have to distinguish between the two. Sometimes the programmer will want to read bytes, sometimes characters, and sometimes tokens - like the textual representations of doubles or booleans.
-
Treat multiple sources of input in a uniform way Input can come from many different sources: files, network connections, standard in, strings, arrays of bytes, arrays of characters, pipes. etc. We saw in writing C that writing functions that took an
FILE *stream argument, which could equally take ainputfilestreamorstdin, was a powerful idea. This is just an example of the power of treating multiple sources of input in a uniform way, i.e. with one programming construct that applies to many different actual sources of input. -
Flexibility to add new operations, improve efficiency, or modify input streams on the fly: With something as universally used as stream-oriented I/O, there’s no way to design a system that will meet everyone’s needs all of the time. Therefore, the system needs to provide programmers the flexibility to change how things work without abandoning or breaking the whole system.
Bytes, Chars or Tokens? #
The Java I/O design takes into account issue 1 from the above in a typically OOP way, by having three separate classes of input objects.
- abstract class InputStream for byte-based input.
int read(); //returns an int from 0 to 255 //or -1 if at the end of the stream int read(byte[] b, int off, int len); void close(); ... - abstract class Reader for character-based input
int read(); //returns an int from 0 to 65535 //or -1 if at the end of the stream int read(char[] cbuf, int off, int len); void close(); ... - class Scanner for token-based input
String next(); int nextInt(); double nextDouble(); ...
As a programmer, you have to figure out how you want to read data in. Would you like to read a byte or chunk of bytes at a time? Then you want an InputStream object. Would you like to read a character or chunk of characters at a time? Then you want a Reader object. Would you like to read a token at a time, e.g. a double at a time or String at a time or boolean at a time? Then you want a Scanner object. So far, we’ve focused on reading tokens (an int or word or float) at a time.
Treat multiple sources of input in a uniform way #
Here’s how the Java IO system uses OOP to allow multiple sources of input to be treated in a uniform way. First of all, the InputStream and Reader classes are abstract. They are the roots of class hierarchies. Specific sources of bytes of data give rise to classes that extend InputStream. For example, in the API we have:
InputStream
^ ^
/ \
/ \
FileInputStream ByteArrayInputStream
So if, for example, you want to write code to search for the bytes 0x7F 0x45 0x4C 0x46, which indicates the beginning of a Executable and Linkable Format (ELF) file (i.e. an executable file in Unix, or what gcc compiles a program into 😜), you would write your method to take an InputStream argument. That way the same method works for both files and byte arrays.
Similarly, specific sources of characters give rise to classes that extend Reader. For example, in the API we have:
Reader <-._
^ ^ \____
/ \ \
/ \ \
StringReader CharArrayReader InputStreamReader
So, if you wanted to write code to count the number of non-alphabetical characters in text, you would write that method to take a Reader argument. That way the same method works for Strings, arrays of chars and (and this is interesting!) any InputStream — because we can make an InputStream the source of characters for a Reader via the InputStreamReader class! If you look at the API documentation for InputStreamReader, the InputStreamReader constructors take an InputStream as a parameter. And yes, if you’re wondering System.in is an InputStream, so you can create an InputStreamReader from System.in.
Finally, we have our good friend the Scanner.
Class Scanner has constructors that take InputStreams or Readers as arguments. So if you wanted to write code to do something like add all the integers in some text, you would write that method to take a Scanner as an argument. That way it would work with files, byte arrays, char arrays or Strings. Putting this together, if you have a file whose name is “data.txt” and you want to read in tokens from it (e.g. ints and double and booleans and strings), you would create a scanner for it like this:
Scanner sc = new Scanner(new InputStreamReader(new FileInputStream("data.txt")));
/* \_____________________________/
an InputStream whose bytes
come from file data.txt
\____________________________________________________/
a Reader whose chars come from the bytes in data.txt
\_________________________________________________________________/
a Scanner whose tokens are made up of chars whose bytes come from data.txt
*/
There are some shortcuts to all of this. So-called “convenience methods” to make, for example, a Reader directly from a file name.
Two important points here:
- Technically there is no
Scannerconstructor that takes aReaderas a parameter. Instead, it takes an object that implements theReadableinterface. However,ReaderimplementsReadable, so this constructor works withReaders, but is in fact a bit more general than that.- The
Scannerconstructor that takes an InputStream as an argument is actually just a convenience thing. You only really need the constructor that takes aReaderas an argument. Why is that enough?
Flexibility to add new operations, improve efficiency, or modify input streams on the fly #
Finally we get to the third and last of our design goals: the flexibility to add new operations, improve efficiency, or modify input streams on the fly. When we want to modify or extend functionality in OOP, what do we always do? We use inheritance. I’ll give you two examples of where this is done in the Java API, one to modify behavior and one to add functionality.
The first is the class BufferedReader. The issue BufferedReader addresses is this: when a call to read() is made for a Reader that has, for example, a file as its ultimate source for data, that call results at some lower level in a system call to fetch that byte. At this low level, however, fetching a byte-at-a-time is tremendously inefficient. It typically takes as much time to fetch something like 1024 or 2048 bytes as it does a single byte. Therefore, it would be nice to have a variant of Reader that would fetch, say, 1024 bytes into a buffer the first time read() is called, then dole those out one-at-a-time for each read() call until the buffer is emptied. Only then would it go back to fetch more bytes from the lower-level — another chunk of 1024. That’s what the class BufferedReader does. What’s kind of funny is that it does it as a wrapper around another Reader. In other words, BufferedReader is a Reader that takes a Reader and wraps it in this buffering scheme. So for example, if you had a file data.txt to read tokens (e.g. integers) from, and you were worried about performance, you might create your Scanner like this:
Scanner sc1 = new Scanner(new BufferedReader(new InputStreamReader(new FileInputStream("data.txt"))));
The BufferedReader will make calls like read(buff,0,1024) to its underlying InputStreamReader, which will make a call like read(buff,0,1024) to its underlying FileInputStream, which will result in a lower-level system call to fetch the next 2024 bytes from the file. The object oriented design of Java’s I/O package makes this possible. By deriving BufferedReader from Reader, the Java authors provide modified functionality that can be used anywhere a regular Reader can be used.
The second example to look at is the class LineNumberReader, which is much easier to explain. Sometimes you want to be able to ask what line you’re on as you read input. The BufferedReader is a great class that buffers the input for you, making the reading process more efficient by making less calls to the input stream. However, it doesn’t track things like what number you are on. It’s an extra piece of functionality you might wish a BufferedReader had. The class LineNumberReader extends BufferedReader to provide just that, and it takes any Reader as input. We can create one like this:
LineNumberReader reader = new LineNumberReader(new InputStreamReader(new FileInputStream("data.txt")));
… and whenever you want to know what line number you’re on you can call r.getLineNumber(). Once again, the object oriented design of Java’s I/O package makes this possible. By deriving LineNumberReader from BufferedReader, the Java authors provide new functionality that can use any type of input stream, yet still track the lines that have been processed. What if you still want a Scanner? You can create one for each line that your new reader returns:
LineNumberReader reader = new LineNumberReader(new InputStreamReader(new FileInputStream("data.txt")));
String line = reader.readLine();
while( line != null ) {
Scanner sc = new Scanner(line);
// read your tokens for whatever you need!
// ...
line = reader.readLine();
System.out.println("You're on line " + reader.getLineNumber());
}
We could dive deeper into the weeds here and talk about what would happen if you wrap a Scanner around a LineNumberReader (new Scanner(new LineNumberReader(...))). While this is allowed (it’s a Reader!), you kind of lose the line number functionality because the Scanner is using the buffered characteristics of the reader here, and it reads ahead while you’re calling its next() methods. If you ask for the line number, it will often be too far. Still, it could be useful in getting the general line number if not the precisely correct one.
And then …
And then we should probably look at the Errors and Exceptions that all these > methods from all these classes throw … but we won’t. You can do that on your own!
A short note on output #
Output is fundamentally a bit easier than input. Why? Because with output your code knows what it wants to write, so it controls the outgoing bytes. With input, your code doesn’t know what’s coming. It must react and adapt to the incoming bytes. So we’re not going to describe output in as much detail.
Similar to the input case, we have two separate hierarchies for output: the hierarchy rooted at OutputStream, which is for byte-oriented output, and the hierarchy rooted at Writer, which is for character-oriented output. The distinction is a bit blurrier than for the input case, because the class PrintStream, which is derived from OutputStream, provided methods for writing int’s, double’s, String’s, etc., as does PrintWriter, which is derived from Writer. The distinction has to do with how characters are encoded as bytes: PrintStream using the JVM’s default encoding and PrintWriter allowing the programmer to independently specify that encoding. These are distinctions we won’t go into here. Note, however, that System.out and System.err are both PrintStream objects.
Just to round out this example, let’s look at what it would take to write “Hello World” to a file.
PrintWriter pw = new PrintWriter(new File("output.txt"));
//Note that we are not specifiying a character set. Java defaults to unicode
pw.println("Hello World!");
pw.close(); //close the file
As you can see, printing/writing is much more straightforward than reading.
Networking #
What is the internet? #
The Internet by definition is a network of networks composed of computers. As a non-technical term, we use the term Internet as a catchall for all connected computers, but in technical terms, it is just one part of a larger ecosystem of networks and protocols that enable the sharing of information.
This is not a class on networking or the internet, but the ability to communicate over a network is an integral part of modern programming that fits nicely within the OOP models of IO we’ve been discussing with Java so far. But, to really understand network programming, you have to first have a decent understanding of the protocols that underly the Internet, and one thing you learn quickly about network programming is that the protocol is king. Understanding the protocols is will make you a better programmer.
Packet Switching #
The internet is a packet switched network. A packet is defined as follows:

All packets have a header, which stores the address or destination of a packet, and a payload which stores the data or message of the packet. The switching part of packet switching is that at network devices, like routers and switches, the packet arrives, and based solely on the header of the packet, the device knows where to send the data next. There are no pre-defined routs for data but the protocols ensure that the next hop in the path to the destination can be determined. As you might imagine, in such a model, addressing becomes very important.
The TCP/IP Protocol Stack #
The Internet is modelled as a protocol stack where each protocol defines a different interaction layer. Information flows up and down the protocol stack, and at each layer, a different protocol comes to bare for forwarding the packet onward to the next hop.
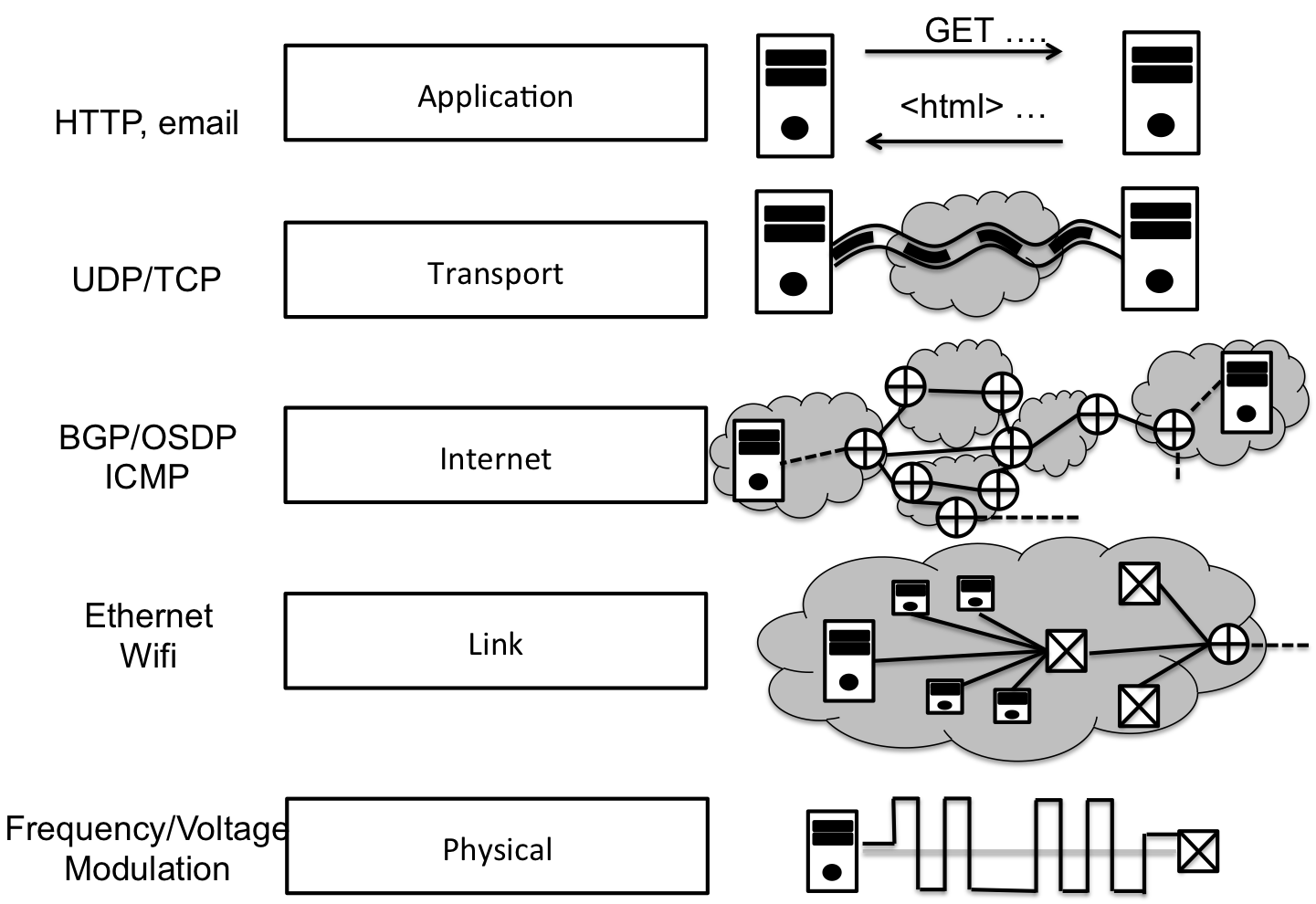
Each layer has different goal in mind. Starting with the physical layer, the main purpose is to actually transmit 1’s and 0’s over medium, like a wire. The link layer adds protocols for how the medium is shared across many connected devices, as well as error correction. An example of protocols on the link layer is ethernet or wifi.
The internet and transport layer of are particular interest in this class because you will interact directly with these protocol through their addressing schemes. The purpose of the internet layer is to inter-connect networks; for example,e GW has a network, and if you want to send data to Google, your packets must traverse GW network and potentially many other federated networks before finally reaching a server at Google. The internet layer both describes the protocols for how networks inter connect with each other and the way that computers are identified, via the internet protocol address or ip address.
At a certain point, though, two processes running on different computers are actually sending and receiving data across the vastness of the Internet. The transport layer provides an abstraction for those two process to apear as if they are communicating directly with each other. Since many process can be communicating on the network at the same time, the transport layer also provides a mechanism, called ports, to differentiate communication destined for one process versus another.
Finally, at the application layer, additional protocols are available depending on the task at hand. For example, SMTP is used to transmit email messages and HTTP is used to download web content and BitTorrent is used to pirate music and videos :) From a generic programmers perspective, the application layer is the domain where we get to choose what data is sent and received and how that data is interpreted; the systems programming perspective also concerns itself with system calls that enable that communication.
Internet Addressing #
Each layer has its own addressing scheme and information needed to perform routing/switching. This information is traditionally encoded within the header of the packet. There are two key addressing systems that we will use in this class, ip addresses and ports. Additionally, we also refer to computers by name, a domain name, which must be translated into an address.
IP Addresses #
An ip address is a 4-byte/32-bit number in Version 4 of TCP/IP protocol. We usually represented in a dotted quad notation:
4-bytes
_____________
/ \
192.168.128.101
\_/
|
1 byte
A byte is 8-bits, and thus can represent numbers between 0-255, which is why ip addresses do not have numbers greater than 255. The ip address is hierarchical where bytes to the left are more general while bytes to the right are more general. Based on a subset of the bytes, routers can determine where to send a packet next.
Domain Names and Hosts #
While IP addresses are somewhat usable, it is quite a burden to memorize the ip address of all the computers we might want to vist on the web. For exampel, while I might know the ip address of a single computer off hand, e.g., “10.53.37.142” is the ip address of a lab machine, I can’t recall the ip address of Google or Facebook or much of anything else.
Instead, we use domain names to identify a networked device. A hostname, is a dotted string of names, usually ending in the canonical .com or .org or .edu or .gov or etc. For example, the domain name for Google is google.com, but the Internet does not function on domain names. It needs IP addresses. A separate protocol called the Domain Name Service or DNS is tasked with converting domain names into IP addresses.
We can access the DNS system on Unix through the host command. For example, suppose we wanted to learn the IP address of google.com:
#> google.com
google.com has address 74.125.228.110
google.com has address 74.125.228.103
google.com has address 74.125.228.96
google.com has address 74.125.228.99
google.com has address 74.125.228.104
google.com has address 74.125.228.101
google.com has address 74.125.228.102
google.com has address 74.125.228.97
google.com has address 74.125.228.100
google.com has address 74.125.228.105
google.com has address 74.125.228.98
google.com has IPv6 address 2607:f8b0:4004:803::1003
google.com mail is handled by 30 alt2.aspmx.l.google.com.
google.com mail is handled by 40 alt3.aspmx.l.google.com.
google.com mail is handled by 20 alt1.aspmx.l.google.com.
google.com mail is handled by 10 aspmx.l.google.com.
google.com mail is handled by 50 alt4.aspmx.l.google.com.
The output may not be what you expect. There are many, many different IP addresses available to server google.com, and this is by intention to balance the load of request across multiple machines. In fact, every time you rerun host, you’ll find that you get a different set of IP address:
#> host google.com
google.com has address 74.125.228.104
google.com has address 74.125.228.101
google.com has address 74.125.228.102
google.com has address 74.125.228.97
google.com has address 74.125.228.100
google.com has address 74.125.228.105
google.com has address 74.125.228.98
google.com has address 74.125.228.110
google.com has address 74.125.228.103
google.com has address 74.125.228.96
google.com has address 74.125.228.99
google.com has IPv6 address 2607:f8b0:4004:803::1003
google.com mail is handled by 50 alt4.aspmx.l.google.com.
google.com mail is handled by 30 alt2.aspmx.l.google.com.
google.com mail is handled by 40 alt3.aspmx.l.google.com.
google.com mail is handled by 20 alt1.aspmx.l.google.com.
google.com mail is handled by 10 aspmx.l.google.com.
If we were to query a less used domain name, one that isn’t serving as much traffic as google, we get IP addresses that are a bit more sane. For example, let’s see what the IP addresses are for www.cs.gwu.edu:
$ host www.cs.gwu.edu
www.cs.gwu.edu is an alias for www2old.gwu.edu.
www2old.gwu.edu has address 161.253.128.45
Interesting, you can see that www.cs.gwu.edu is an analias for another domain www2old.gwu.edu, which in turn has a stable IP address 161.253.128.45.
Ports #
The last bits of addressing relevant to this class is the port address. While the IP address is used to deliver packets to a destination computer, the port address is used to deliver the packets on the computer to the right process. Consider that a single computer all share the same IP address, there are many different applications using that connection at the same time. You might have multiple web pages open with email and playing games and etc, each of those interactions is performed by a separate process but all the data arrives at the computer through a single point.
The port address is a way for the Operating System to divide up the data arriving from the network based on the destination process. Additionally, ports tend to be tightly coupled with applications. For example, to initiate a HTTP connection for web browsing, you connect using port 80; to initiate a secure shell connection with ssh, you connect using port 22; and, to initiate a connection to send email, you connect using port 25, and so on. What makes ports important is that all those services, web server, ssh, and email, can all be running on the same computer. The ports allows the operating system differentiate traffic for each application.
Client/Server Model #
Most interactions of applications are dictated by the client-server model. In this model there exists clients who are requesting a services for a server.
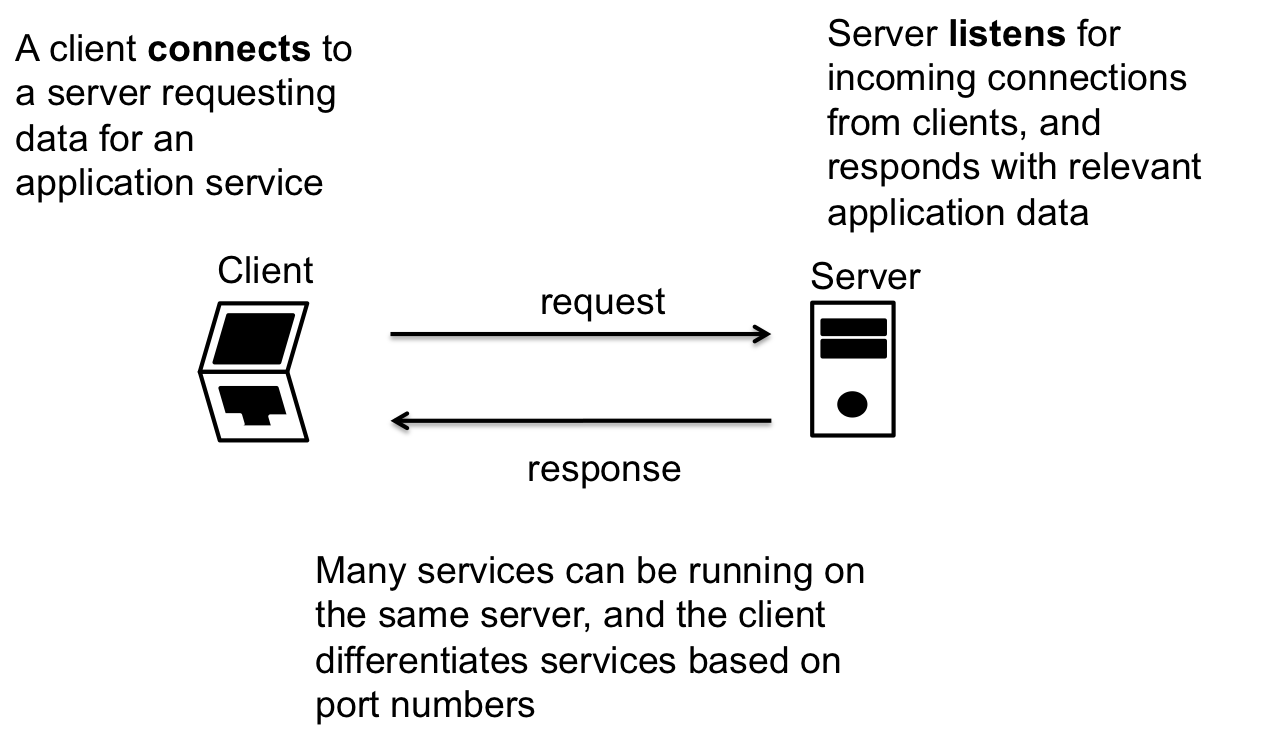
In the model, we describe clients as connecting to servers and servers listening to incoming connections. When a connection is established, or data is received, the server replies to the client with data as required by the application protocol.
While this class will focus on the client server model, there are other models of network interaction. For example, the peer-to-peer model is when clients act as both client and servers. This is common for many distributed systems, such as BitTorrent or Skype.
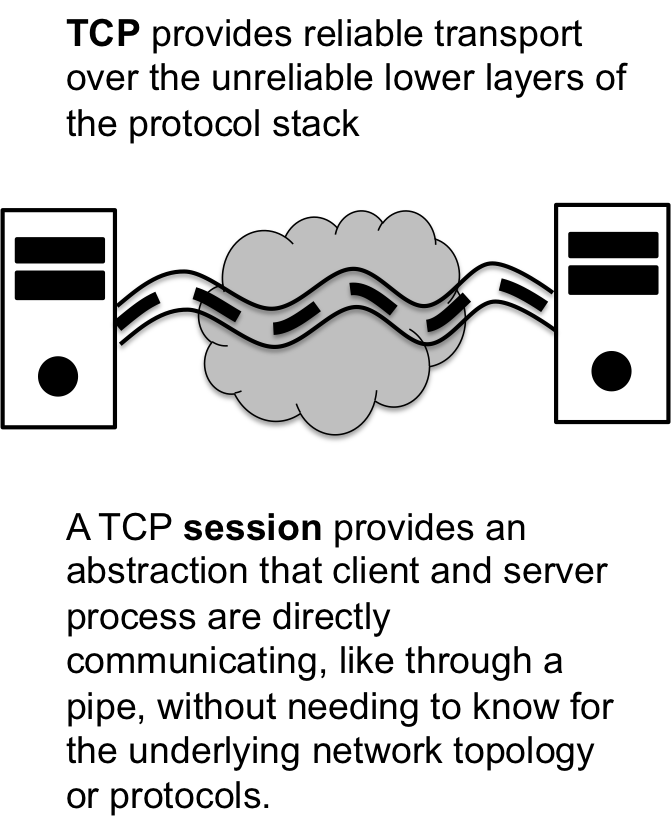
Reliable Transportation: TCP #
The client server model fits into the protocol stack at the transport layer. There are typically two types of transport available for programmers, reliable and unreliable transport. Interestingly, none of the protocols in lower layers ensure any reliability — at any time packets can be drop, misrouted, delayed, or generally deformed without notice. The fact that such things can happen on the network is actually a positive because the lower layers can be much more efficient without having to worry about reliable delivery.
Unreliable Transport: UDP #
Reliable transport has a cost, though. The cost is the retransmission of lost or deformed packets and acknowledgments of properly received packets. In order to have reliable transportation, all information must be properly acknowledged upon receipt and if a packet was not properly received, then it must be retransmitted. The result is that there exists a significant overhead, and this is worsened by the fact that not all communication needs to be reliable — dropping a few packets here and there never killed anyone, yet.
The complementary protocol to TCP is UDP or User Datagram Protocol, which is an unreliable transport mechanism. The UDP protocol, or DATAGRAM protocol, does not make any guarentees about the delivery if a packet. It might get there … or it might not. Datagram protocols are not session driven either; without reliability, the client and the server need not stay in sync to ensure that all messages are acknowledged. Instead, a server just listens for incoming data from clients and thats that.
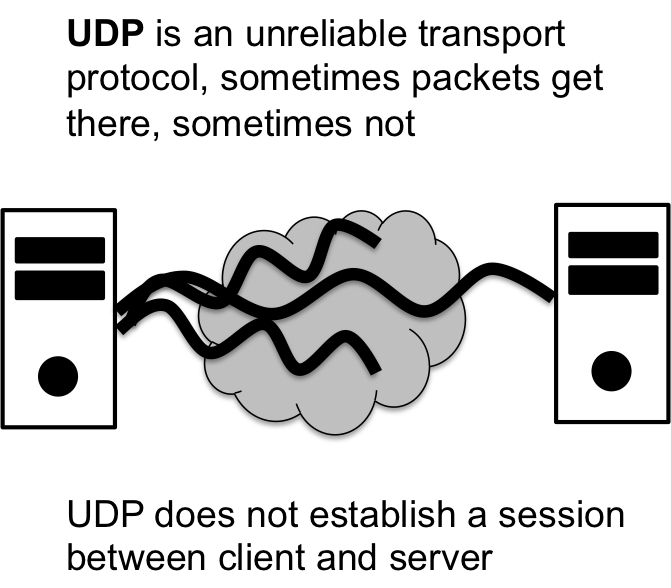
You might be wondering when would this ever be useful? UDP is quite common for a number of applications; for example, live audio streams. There is no need for audio streams to be reliable, if you miss a packet, so what, you’ll just get the next one and keep playing the music. However, if you were to do this reliably, you’d have to stop the music while missed data was retransmitted, and the result is you might keep getting further and further behind in the live stream.
Networking Command Line Tool: netcat #
Before we start to write programs to use sockets, it is useful to learn how to test these programs using the “swiss army knife” of networking command line tools, netcat. Also, you can use a tool called netstat to monitor your open socket connections. As a programmer, these tools are often indispensable for debugging and understanding the functionality of your program.
Later we’ll use this to test the programs we are writing
Note that on a mac
netcatcommand is run by usingnc
netcat client #
When working as a client, netcat takes two arguments:
netcat dest port
The dest is a destination address, which can either be a IP address as a dotted quad or a domain name. The port is a number representing the port address. This is all we need to make netcat act like a web client, so let’s connect to a web server
#> netcat www.cnn.com 80
GET /index.html
<!DOCTYPE HTML>
<html lang="en-US">
<head>
<title>CNN.com - Breaking News, U.S., World, Weather, Entertainment & Video News</title>
<meta http-equiv="content-type" content="text/html;charset=utf-8"/>
<meta http-equiv="last-modified" content="2014-04-03T13:48:56Z"/>
<meta http-equiv="refresh" content="1800;url=http://www.cnn.com/?refresh=1"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge"/>
<meta name="robots" content="index,follow"/>
(...)
What we’ve just done is establish a TCP connection on port 80, the HTTP port for web traffic, and make a request to the HTTP server to send us the main page for cnn.com. And it works!
netcat Server #
netcat can also act as a sever by listening for incoming connections on a given port. You do this with the -l option:
#> netcat -l 1845
There is now a service running on 1845, netcat, and we can connect to it using another netcat client.
#> netcat -l 1845
Hello
What's your name?
adam
me too, how strange.
strange ......
#>
#> netcat localhost 1845
Hello
What's your name?
adam
me too, how strange.
strange ......
^C
#>
</div>
The domain name localhost refers to the current computer, this way we don’t always have to remember the IP address. In the above example, information is typed back and forth between the netcat servers and clients.
Socket Programming in Java #
Now that you have a good idea of how networking works, we turn our attention to how Java enables access to networking API. At this point, it shouldn’t surprising you that this occurs via Objects and that it fits into an already established framework of I/O. That means communicating over the network in a programmatic way is similar to read/writing to files, except the endpoint is not a file, but rather a remote computer.
Java divides socket programming into server and client programming. There are two main classes
We’ll review using both below. And if you want more information, Oracle offers a nice tutorial of using sockets
The Socket class #
In Java, the Socket class is used as the client socket in a two-way communication with a server. Key to this idea is that the socket is connected to the server at a ipaddress/host and port. The main constructor you’ll use is
Socket(String host, int port);
//Creates a TCP stream socket and connects
//it to the specified port number on the named host.
Note that all
Sockets in java are TCP (SOCKSTREAM) sockets, if you want to use a different socket type, you’ll need to use one of the other socket classes, likeDatagramSocket.
Importantly, the Socket is to connect to the server, but communication with the server is a two-way procedure. So once we connect to the server, we can both read and write to the socket via the socket’s InputStream and OutputStream. And like with other I/O we can wrap those streams in other buffered readers/writers.
Let’s start with a “Hello World” example of a client connecting to a server and writing “Hello World”. Our basic program looks like the following
import java.util.*;
import java.net.*;
import java.io.*;
public class HelloSocket{
public static void main(String args[]){
Socket sock=null;
try{
sock = new Socket("localhost",2021);
}catch(Exception e){
System.err.println("Cannot Connect");
System.exit(1);
}
try{
PrintWriter pw = new PrintWriter(sock.getOutputStream());
pw.println("HelloWorld");
pw.close(); //close the stream
sock.close();//close the socket
}catch(Exception e){
System.err.print("IOException");
System.exit(1);
}
}
}
Note that we need the try/catch blocks because there are a number of errors that can occur when dealing with I/O. If we were to run this program, we first can start a netcat server to receive the connection on our localmachine and then run the java program.
$ netcat -l 2021
HelloWorld
$ java HelloSocket
The socket is two-way, so we can also “read” for input after having written to the socket. This is a small expansion of the above program
try{
PrintWriter pw = new PrintWriter(sock.getOutputStream());
pw.println("HelloWorld");
pw.flush(); //flush the output (recall PrintWriters buffer)
BufferedReader in =
new BufferedReader(
new InputStreamReader(sock.getInputStream()));
String reply = in.readLine();//read a line from ther server
System.out.println("Server said: "+reply);
pw.close(); //close the stream
in.close();//close the input stream
sock.close();//close the socket
}catch(Exception e){
System.err.print("IOException");
System.exit(1);
}
Now when we run the program, we can type input after “HelloWorld” which get’s written to our client.
$ netcat -l 2021
HelloWorld
Goodbye cruel world
$ java HelloSocket
Server said: Goodbye cruel world
The ServerSocket class #
The server side of this works pretty much like the client side, except for an additional step of the server needing to accept an incoming connect. The key class is the ServerSocket which we initialize like so
ServerSocket serverSocket = new ServerSocket(portNumber);
The portNumber is which port we want to be listening for on an incoming connection. Once the serverSocket is established we call accept(), which returns a new Socket that is used to communicate with that client.
Socket clientSocket = serverSocket.accept();
Importantly, the server socket can accept more connections from other client sockets. That is why a new socket is created for each client.
To demonstrate this, we want to create a “Hello World” server that writes “Hello World” every time you connect to it. We put the accept call in a loop.
import java.util.*;
import java.net.*;
import java.io.*;
public class HelloServer{
public static void main(String args[]){
ServerSocket serverSock=null;
try{
serverSock = new ServerSocket(2021);
}catch(Exception e){
System.err.println("Cannot open server socket");
System.exit(1);
}
try{
while(true){
Socket clientSock = serverSock.accept();
System.out.println("Connection from: "+clientSock.getRemoteSocketAddress());
PrintWriter pw = new PrintWriter(clientSock.getOutputStream());
pw.println("Hello World");
pw.close(); //close the stream
clientSock.close();//close the socket
//loop and get the new connection
}
}catch(Exception e){
System.err.print("IOException");
System.exit(1);
}
}
}
Note that we can easily see who is connecting to the server by retrieving the remote socket address and print that out. This gives us the following output, where we continually connect to the server via netcat.
$ netcat localhost 2021
Hello World
$ netcat localhost 2021
Hello World
$ netcat localhost 2021
Hello World
$ java HelloServer
Connection from: /127.0.0.1:62800
Connection from: /127.0.0.1:62801
Connection from: /127.0.0.1:62802
Each connection comes from 127.0.0.1, which is the IP address used when connecting within a single localhost computer. Also note that the port changes each time, that’s because once the connection is established, the server is still listening on the original port 2021, so this new connection should use a different port
Threaded Echo Socket Server #
The final step in programming a sockets is to consider the threaded socket server. A threaded socket server starts a new thread for each thread so that the main thread can continue to listen to incoming connections. To understand why this would be needed, consider that in the example above that while the server is printing to the client, another client may be queued to connect. In this example, this is probably fine because the action the server does is somewhat complex, but let’s consider a more complex server that echos back to the client anything written to the socket until the client closes the socket.
You should be able to trace the function of this program now …
import java.util.*;
import java.net.*;
import java.io.*;
public class EchoSocketServer{
ServerSocket serverSock;
public EchoSocketServer(int port){
try{
serverSock = new ServerSocket(port);
}catch(Exception e){
System.err.println("Cannot establish server socket");
System.exit(1);
}
}
public void serve(){
while(true){
try{
//accept incoming connection
Socket clientSock = serverSock.accept();
System.out.println("New connection: "+clientSock.getRemoteSocketAddress());
//start the thread
(new ClientHandler(clientSock)).start();
//continue looping
}catch(Exception e){} //exit serve if exception
}
}
private class ClientHandler extends Thread{
Socket sock;
public ClientHandler(Socket sock){
this.sock=sock;
}
public void run(){
PrintWriter out=null;
BufferedReader in=null;
try{
out = new PrintWriter(sock.getOutputStream());
in = new BufferedReader(new InputStreamReader(sock.getInputStream()));
//read and echo back forever!
while(true){
String msg = in.readLine();
if(msg == null) break; //read null, remote closed
out.println(msg);
out.flush();
}
//close the connections
out.close();
in.close();
sock.close();
}catch(Exception e){}
//note the loss of the connection
System.out.println("Connection lost: "+sock.getRemoteSocketAddress());
}
}
public static void main(String args[]){
EchoSocketServer server = new EchoSocketServer(2021);
server.serve();
}
}
On your own, can you write an EchoClient and connect it to the server so that they go back and forth for ever!!!